RETHINKING DATA SELECTION AT SCALE: RANDOM SELECTION IS ALMOST ALL YOU NEED
[논문] RETHINKING DATA SELECTION AT SCALE: RANDOM SELECTION IS ALMOST ALL YOU NEED
LLM 성능, '족집게 과외'보다 '랜덤'이 나은 이유
LLM을 우리 서비스에 맞게 튜닝하고 싶은데, 어떤 데이터를 먹여야 최고 성능이 나올까요? "이왕이면 좋은 데이터만 골라서 학습시켜야지!"라고 생각하는 것이 인지상정입니다. 그래서 많은 엔지니어들이 데이터의 '품질'과 '다양성'을 평가하는 복잡한 알고리즘을 연구하며 '족집게 과외'를 시키려고 노력해왔죠.
그런데 만약, 수많은 시간과 비용을 들인 그 '똑똑한' 방법이 단순한 '무작위 선택'보다 별로 나을 게 없다면 어떨까요?
최근 발표된 한 논문("RETHINKING DATA SELECTION AT SCALE")은 바로 이 허를 찌르는 질문을 던집니다. 이 글에서는 개발자 여러분이 LLM 튜닝에 쏟는 노력을 10분의 1로 줄여줄, 이 논문의 충격적인(?) 발견과 실용적인 지침을 재미있게 풀어보겠습니다.
LLM 튜닝, '족집게 과외'의 세계
본론에 들어가기 전에, LLM 튜닝의 기본 개념부터 가볍게 짚고 넘어가죠.
1. LLM의 학습 과정: 전교 1등 만들기
LLM을 만드는 과정은 두 단계로 나뉩니다.
- 사전 학습 (Pre-training): 세상의 모든 책을 읽고 보편적인 지식과 언어 능력을 갖춘 '전교 1등'을 만드는 과정입니다. 이미 똑똒한 상태죠.
- 미세 조정 (Fine-Tuning, SFT): 그런데 이 전교 1등이 우리가 원하는 방식으로 말을 하진 않습니다. 그래서 특정 시험(e.g., 고객 응대, 코드 작성)에 대비시키기 위해
질문-답변형식의 '족집게 기출문제'를 풀게 하는 과정이 바로 SFT입니다. SFT의 목표는 모델을 더 똑똑하게 만드는 게 아니라, 우리가 원하는 방향으로 '말 잘 듣게' 만드는 것입니다.
2. 데이터 선택: 족집게 요약본 만들기
수백만 개의 문제(데이터)를 전부 풀게 하면 좋겠지만, 시간과 비용이 엄청나겠죠. 그래서 우리는 이 중에서 가장 효과적인 문제들만 모아 '족집게 요약본'을 만들고 싶어 합니다. 이것이 바로 데이터 선택(Data Selection)입니다.
지금까지는 더 똑똑한 모델(GPT-4 등)을 심사위원으로 모셔와 데이터의 품질 점수를 매기거나, 학습시킬 모델에게 직접 문제를 풀어보게 해서 "이 문제가 너한테 어렵니, 쉽니?"를 물어보는 등 정교한 방법들이 유행했습니다.
"그런데, 그 방법이 정말 효과가 있나요?"
이 논문의 저자들은 근본적인 의문을 제기합니다. 기존 연구들은 기껏해야 수만 개짜리 소규모 데이터셋에서나 효과를 봤는데, 실제 현장에서 쓰는 수백만 개짜리 대규모 데이터셋에서도 통할까?
결과는 놀라웠습니다.
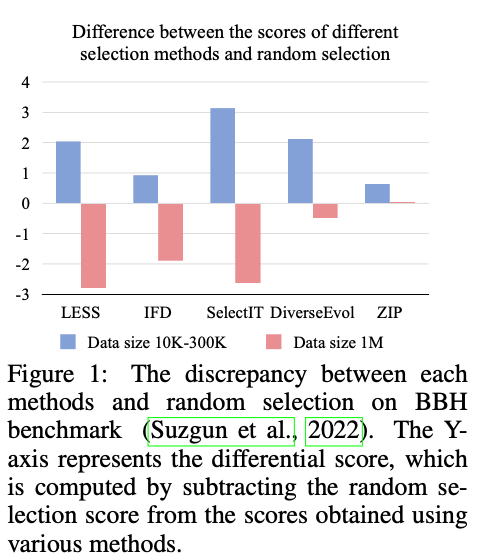
이 이미지는 다양한 데이터 선택 방법과 무작위 선택 간의 성능 차이를 시각적으로 보여줍니다. 소규모 데이터셋에서는 기존의 데이터 선택 방법들이 무작위 선택보다 뛰어난 성능을 보였습니다. 하지만 대규모 데이터셋에서는 이러한 방법들이 무작위 선택과 비슷하거나 오히려 낮은 성능을 나타내어, 대규모 SFT에서는 무작위 선택의 효율성을 강조합니다.
그림에서 보듯, 온갖 복잡한 계산을 동원한 '똑똑한' 방법들이 5번의 무작위 선택 결과와 비교했을 때, 통계적으로 유의미한 차이를 만들지 못했습니다. 오히려 성능이 더 떨어지는 경우도 있었죠. 비싼 돈 주고 족집게 과외를 시켰는데, 그냥 문제집 아무 페이지나 펴서 공부한 것과 성적이 비슷한 셈입니다. 이게 어떻게 된 일일까요?
핵심 발견 3가지: 우리가 놓치고 있던 것
1. 데이터가 충분히 많고 다양하면, '무작위'가 진리다
왜 이런 결과가 나왔을까요? 비유를 들어보죠.
훌륭한 셰프가 거대한 팬트리에 온갖 신선하고 다양한 식재료를 가득 채워두었습니다. 이 경우, 눈을 감고 아무 재료나 한 움큼 집어도 꽤 근사한 요리가 나올 확률이 높습니다.
대규모 데이터셋이 바로 이 '거대한 팬트리'와 같습니다. 데이터가 100만 개 수준으로 충분히 많고, 출처도 다양하다면 무작위로 샘플링하는 것만으로도 원본 데이터셋의 좋은 특성(다양성, 품질)이 자연스럽게 유지됩니다. 굳이 비싼 알고리즘으로 "최고의 당근" 하나를 고르려 애쓸 필요가 없는 것이죠.
2. '품질'보다 중요한 것은 '다양성'이다
오히려 특정 기준으로 '최고 품질'의 데이터만 고집하는 것이 독이 될 수 있습니다. 예를 들어, '간결하고 명확한 답변'만을 고품질로 정의하고 데이터를 고르면, 모델은 복잡하고 긴 설명이 필요한 질문에 제대로 답하지 못하는 '편식쟁이'가 될 수 있습니다.
'최고의 학생' 몇 명만 가르치는 선생님보다, '다양한 수준의 학생'들을 가르쳐본 선생님이 더 유능한 것과 같은 이치입니다.
실제로 논문에서는 품질 기반 선택 전략에 K-means 클러스터링을 이용해 강제로 다양성을 확보해주자 성능이 크게 오르는 것을 확인했습니다. 핵심은 편식하지 않고 골고루 먹이는 것이었습니다.
3. 진짜 비밀 병기: '토큰 길이'
연구진은 실험 중 재미있는 사실을 발견합니다. 데이터 품질은 좀 떨어져도 평균 텍스트 길이가 긴 데이터셋으로 학습한 모델이 의외로 성능이 더 좋았던 것이죠. 여기서 착안한 가설은 대박을 터뜨립니다.
"데이터의 '토큰 길이'를 기준으로 데이터를 고르면 어떨까?"
방법은 아주 간단합니다.
- 데이터를 주제별로 묶기 위해 K-means 클러스터링을 수행한다. (다양성 확보)
- 각 클러스터(주제 묶음) 안에서 토큰 길이가 가장 긴 데이터들을 우선적으로 선택한다.
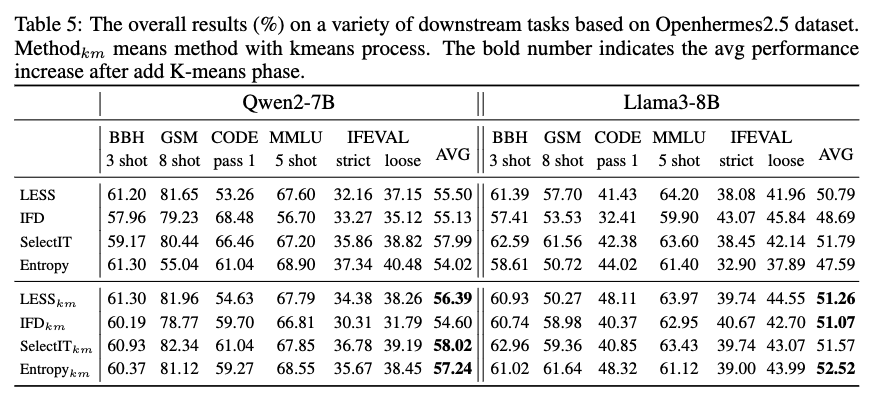
'클러스터링 + 긴 텍스트 선택' 전략과 다른 전략들의 성능 비교. 이 단순한 방법이 다른 어떤 복잡한 방법보다도 안정적으로 높은 성능을, 심지어 전체 데이터를 사용한 것보다도 더 좋은 성능을 보여줍니다.
결과는 놀라웠습니다. 이 단순무식(?)한 방법이 다른 모든 복잡한 알고리즘을 압도했을 뿐만 아니라, 어떤 경우에는 100만 개 전체 데이터를 모두 학습시킨 모델보다도 더 높은 성능을 보였습니다.
왜일까요? '긴 텍스트'는 보통 더 복잡한 개념, 풍부한 맥락, 논리적인 구조를 담고 있을 확률이 높기 때문입니다. 즉, 토큰 길이는 데이터의 '복잡성'을 가늠하는 매우 저렴하고 효과적인 대리 지표(proxy)인 셈입니다.
그래서 개발자들은 이제 뭘 해야 할까? (Action Guideline)
이 논문은 우리에게 매우 명확하고 실용적인 교훈을 줍니다. LLM 튜닝을 위한 데이터 선택, 더 이상 복잡하게 생각하지 마세요.
1. 기본 전략은 '무작위 선택'입니다.
- 수십만 건 이상의 대규모 데이터를 확보했다면, 고민하지 말고 일단 무작위로 샘플링해서 학습시키세요. 이것이 여러분의 가장 강력하고 효율적인 베이스라인입니다. 복잡한 알고리즘에 리소스를 낭비하지 마세요.
2. 성능을 더 끌어올리고 싶다면, '다양성 + 길이'를 기억하세요.
- Step 1: 데이터 임베딩 후 K-means 클러스터링을 돌려 주제별로 그룹을 나눕니다. (다양성 확보)
- Step 2: 각 그룹 내에서 토큰 길이가 긴 순서대로 상위 N%의 데이터를 뽑으세요. (복잡성 확보)
- 이 두 단계만으로 여러분은 최소의 비용으로 최고의 효율을 얻을 수 있습니다.
3. '완벽한 품질'이라는 함정을 피하세요.
- '완벽한 데이터'를 고르려는 노력보다, 다양한 종류의 데이터를 골고루 섞는 것이 모델의 종합적인 문제 해결 능력을 키우는 데 훨씬 중요합니다. 우리의 목표는 특정 문제만 잘 푸는 '편식쟁이'가 아니라, 어떤 상황에도 잘 대처하는 '만능 해결사'를 만드는 것이니까요.
이제 데이터 선택에 쏟았던 에너지를 아껴, 더 창의적이고 중요한 문제에 집중해보는 것은 어떨까요? 때로는 가장 단순한 방법이 가장 위대한 법입니다.
# Comments
아직 댓글이 없습니다. 첫 댓글을 남겨보세요.