How much do language models memorize?
[논문] How much do language models memorize?
LLM의 기억력, 숫자로 측정할 수 있을까? 파라미터당 3.6비트의 비밀
우리가 매일 사용하는 거대 언어 모델(LLM)은 마치 무한한 지식을 담은 블랙박스처럼 보입니다. 하지만 정말 그럴까요? 이 모델이 가진 기억의 물리적 한계는 어디까지일까요? 그리고 모델이 특정 정보를 '기억'하는 것과, 패턴을 학습해 '일반화'하는 것을 어떻게 구분할 수 있을까요?
최근 발표된 한 논문("How much do language models memorize?")은 이 질문에 대한 구체적인 답을 제시합니다. 이 글은 LLM의 블랙박스를 열어 그 기억의 한계와 가능성을 '숫자'로 보여주는 첫 번째 지도와 같습니다. 개발자로서 우리가 사용하는 도구의 근본적인 특성을 이해하는 것은 매우 중요합니다. 이 글을 통해 LLM의 기억 메커니즘을 명확히 이해하고, 그 잠재력과 한계를 가늠해 보세요.
1. 진짜 지식 vs. 단순 암기: LLM의 두 가지 기억
LLM의 '앎'을 이해하려면 먼저 두 가지 개념을 구분해야 합니다. 바로 *의도치 않은 기억(Unintended Memorization)*과 *일반화(Generalization)*입니다.
- 일반화 (Generalization): 우리가 원하는 능력입니다. LLM이 수많은 데이터 속에서 문법, 논리, 사실 관계 등 보편적인 패턴을 학습하는 것을 말합니다. 예를 들어, "프랑스의 수도는?"이라는 질문에 "파리"라고 답하는 것은 일반화된 지식 덕분입니다.
- 의도치 않은 기억 (Unintended Memorization): 훈련 데이터에 있던 특정 문장이나 개인정보 같은 고유한 데이터를 그대로 외워버리는 것입니다. 이는 프라이버시 침해나 저작권 문제로 이어질 수 있는, 우리가 피하고 싶은 부작용입니다.
마치 학생이 시험공부를 할 때, 개념을 이해해서 응용 문제를 푸는 것(일반화)과 교과서 문장을 토씨 하나 안 틀리고 외우기만 하는 것(단순 암기)의 차이와 같습니다. 이 둘을 어떻게 구분하고, 특히 '단순 암기'의 양을 어떻게 측정할 수 있을까요?
2. 기억의 양을 재는 기발한 방법: '압축'의 원리
이 논문은 정보 이론의 근본적인 아이디어, 바로 '압축'에서 해답을 찾습니다. 어떤 데이터를 더 작게 압축할 수 있다는 것은, 그 데이터에 반복되거나 예측 가능한 패턴이 존재한다는 의미입니다.
쉽게 비유하자면:
여러분이
my_text.txt라는 텍스트 파일을 가지고 있다고 상상해 보세요.
- 기준 정보량
HK(x): 이 파일을gzip같은 일반 압축 프로그램으로 압축했을 때의 크기입니다. 이것이 이 텍스트가 가진 순수한 정보량입니다.- 모델을 이용한 압축
HK(x | θ): 이제, 여러분에게 강력한 LLM(θ)이 주어졌다고 합시다. 이 LLM을 참조해서my_text.txt를 압축한다면 어떨까요? 만약 LLM이 이 텍스트의 내용을 이미 잘 '알고' 있다면, 우리는 원본 텍스트와의 차이점(diff)만 담은 아주 작은 패치 파일만으로도 원본을 복원할 수 있습니다. 이 패치 파일의 크기가 바로HK(x | θ)입니다.기억량 =
HK(x)-HK(x | θ)
결국, 모델이 특정 데이터 x를 얼마나 기억하는지는 "모델 덕분에 데이터를 얼마나 더 효율적으로 압축할 수 있는가?"로 측정할 수 있습니다. 압축률이 높을수록, 모델은 그 데이터를 더 많이 기억하고 있다는 뜻입니다.
3. GPT 모델의 기억 용량: 파라미터당 3.6비트
이 방법론을 사용해 연구진은 언어 모델의 '기억 용량(Capacity)'을 측정하는 실험을 진행했습니다. 여기서 '용량'이란 모델이 최대로 저장할 수 있는 총 암기량을 의미합니다.
가장 흥미로운 실험은 완전한 무작위 데이터를 사용한 것입니다. 무작위 데이터에는 학습할 패턴이나 규칙이 없으므로, 모델이 배우는 모든 것은 '일반화'가 아닌 순수한 '암기'일 수밖에 없습니다.
연구진은 다양한 크기의 GPT 계열 모델에 점점 더 많은 양의 무작위 데이터를 학습시켰습니다. 그 결과는 놀라웠습니다.
모델의 크기와 상관없이, 기억량은 특정 지점에서 더 이상 늘어나지 않고 수평선을 그렸습니다. 이것이 바로 해당 모델의 물리적인 기억 용량의 한계입니다.
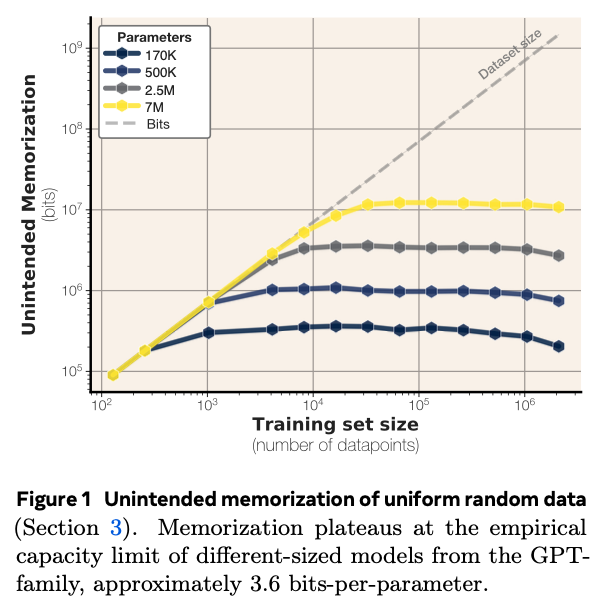
이 한계치를 분석한 결과, GPT 계열 모델은 파라미터 1개당 약 3.5 ~ 4.0 비트(평균 3.6비트)의 정보를 저장할 수 있다는 결론에 도달했습니다.
- 파라미터(Parameter): LLM을 구성하는 인공 신경망의 연결 강도 값으로, 종종 뇌의 '시냅스'에 비유됩니다.
- 3.6 bits/parameter: 이는 LLM의 모든 시냅스가 각각 약 3.6비트의 정보를 저장할 수 있는 작은 저장 공간처럼 작동한다는 의미입니다. 15억 개의 파라미터를 가진 GPT-2 XL 모델이라면, 그 총 기억 용량은 약 675MB (1.5B * 3.6 bits) 정도로 추산할 수 있습니다.
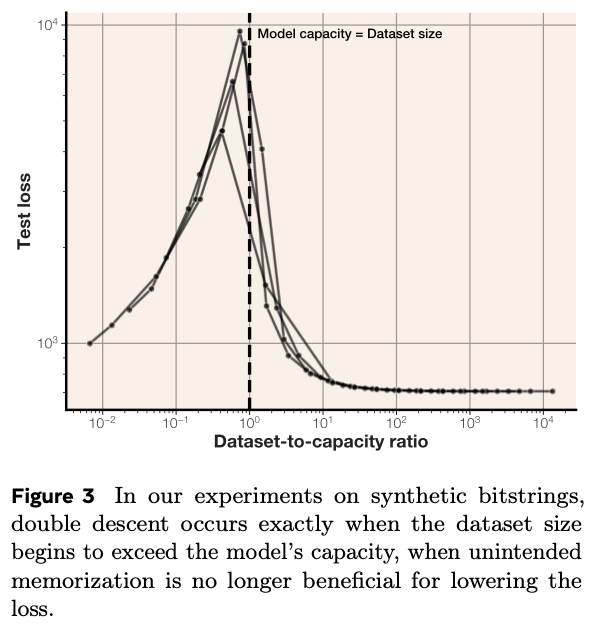
4. 기억이 꽉 차면 무슨 일이 생길까? '이중 하강(Double Descent)'의 비밀
그렇다면 모델의 기억 용량보다 더 많은 데이터를 학습시키면 어떻게 될까요? 이때부터 흥미로운 현상, 바로 '그로킹(Grokking)'과 '이중 하강(Double Descent)'이 나타납니다.
- 초기 단계 (암기 모드): 데이터 양이 모델의 기억 용량보다 적을 때는, 모델이 개별 데이터를 통째로 외우는 것이 손실(loss)을 줄이는 가장 효율적인 방법입니다.
- 포화 단계 (일반화 모드): 데이터 양이 기억 용량을 초과하면, 모델은 더 이상 모든 것을 외울 수 없습니다. 저장 공간이 부족해진 모델은 어쩔 수 없이 데이터들 사이의 공통된 패턴이나 규칙을 찾아내 정보를 '압축'하려 시도합니다. 즉, 암기를 포기하고 일반화를 시작하는 것입니다.
이 전환점에서 모델의 테스트 성능이 일시적으로 나빠졌다가 다시 좋아지는 '이중 하강' 현상이 정확하게 관찰되었습니다. 이는 기억 용량이 모델의 학습 전략을 근본적으로 바꾼다는 강력한 증거입니다.
5. 그래서 이게 왜 중요한가?
이 연구는 우리에게 몇 가지 중요한 시사점을 줍니다.
- 모델의 한계는 측정 가능하다: LLM은 마법이 아닙니다. 파라미터 수에 비례하는 명확한 물리적 기억 용량을 가집니다. 이는 모델을 선택하고 평가할 때 중요한 기준이 될 수 있습니다.
- 데이터셋 크기의 중요성: 모델의 기억 용량에 비해 훈련 데이터가 너무 작으면, 모델은 일반화 대신 암기에 치중할 가능성이 높습니다. 반대로, 매우 큰 데이터셋으로 학습된 모델(대부분의 상용 LLM)은 개별 데이터를 기억하기보다 일반화된 패턴을 학습했을 가능성이 높습니다.
- 멤버십 추론 공격(Membership Inference Attack)의 이해: "이 데이터가 훈련에 사용되었는가?"를 맞추는 공격이 왜 대규모 모델에서 잘 통하지 않는지에 대한 단서를 제공합니다. 데이터셋이 모델 용량을 압도적으로 초과하면, 특정 데이터 하나의 '기억 흔적'은 전체에 희석되어 찾기 어려워집니다.
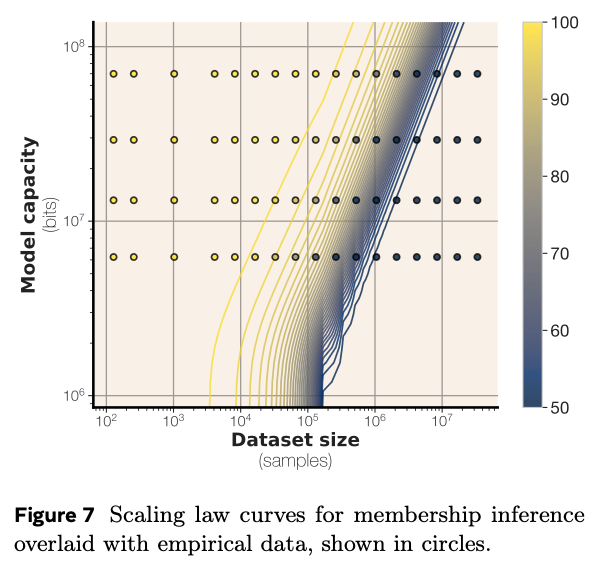
- 곡선은 스케일링 법칙에 의해 예측된 멤버쉽 추론 성능 변화를 나타냅니다.
- 노란색 점(원)은 다양한 모델 크기와 데이터셋 크기 조합에서 측정된 실제 멤버쉽 추론 F1점수를 나타냅니다.
결론: 블랙박스를 향한 첫걸음
이 논문은 '모델의 기억'이라는 추상적인 개념을 '압축률'이라는 구체적인 숫자로 변환하여 측정 가능한 영역으로 끌어왔습니다. 파라미터당 3.6비트라는 수치는 LLM의 용량을 가늠하는 첫 번째 경험적 '눈금자'를 우리에게 제공한 셈입니다.
물론 이것이 LLM의 모든 비밀을 풀어주는 열쇠는 아닙니다. 하지만 우리가 매일 사용하는 이 강력한 도구의 내부 작동 방식을 더 깊이 이해하고, 그 능력과 한계를 보다 명확하게 파악하는 중요한 첫걸음인 것은 분명합니다. 이제 우리는 LLM의 기억력을 막연하게 추측하는 대신, 숫자를 기반으로 논리적으로 분석할 수 있게 되었습니다.
# Comments
아직 댓글이 없습니다. 첫 댓글을 남겨보세요.