Efficient Continual Pre-training for Building Domain Specific Large Language Models
[논문] Efficient Continual Pre-training for Building Domain Specific Large Language Models
LLM 전문가, A to Z 학습은 이제 그만! 10% 데이터로 성능 뛰어넘는 비법
LLM을 특정 도메인(금융, 의료, 법률 등)의 전문가로 만들고 싶으신가요? 아마 가장 먼저 '모델을 처음부터 학습시켜야 하나?'라는 고민과 함께 막대한 비용과 시간에 대한 압박감을 느끼셨을 겁니다. 하지만 만약 전체 데이터의 10%만 사용해서, 100%를 모두 학습시킨 모델보다 더 뛰어난 성능을 낼 수 있다면 어떨까요?
오늘 소개해 드릴 논문, "Efficient Continual Pre-training for Building Domain Specific Large Language Models"은 바로 그 방법을 제시합니다. 이 글을 통해 대규모 자본 없이도 누구나 고성능 도메인 특화 LLM을 구축할 수 있는, 놀랍도록 효율적인 전략을 알아보세요.
1. '일반의'를 '전문의'로 만들기: 지속적 사전학습(CPT)
LLM을 처음부터(from scratch) 학습시키는 것은 의사 한 명을 유치원부터 다시 가르쳐 양성하는 것과 같습니다. 시간과 비용이 어마어마하죠. 지속적 사전학습(Continual Pre-training, CPT)은 훨씬 스마트한 접근법입니다.
CPT는 이미 모든 과목을 훌륭하게 이수한 '일반의'(범용 LLM, 예: Llama)에게 특정 분야, 예를 들어 '심장학' 데이터(도메인 데이터)를 집중적으로 가르쳐 '심장 전문의'(도메인 특화 LLM)로 만드는 과정과 같습니다.
이 방식은 이미 세상의 보편적인 지식과 언어 구조를 알고 있는 모델에서 시작하기 때문에 훨씬 적은 비용과 데이터로 원하는 분야의 전문가를 만들 수 있습니다.
2. 핵심 비결: '양'이 아닌 '질'로 승부하는 데이터 선택
하지만 단순히 도메인 데이터를 전부 모델에 주입하는 것이 최선일까요? 이 논문의 저자들은 "아니"라고 말합니다. 도서관의 모든 책을 읽는다고 시험을 잘 보는 것이 아니듯, 모델에게도 '영양가 높은' 핵심 데이터를 선별해 먹여주는 것이 훨씬 효율적입니다.
이것이 바로 이 논문의 핵심 아이디어입니다. 방대한 도메인 데이터 속에서 모델의 성능을 극적으로 끌어올릴 '알짜배기' 데이터만 골라내는 두 가지 전략을 살펴보시죠.
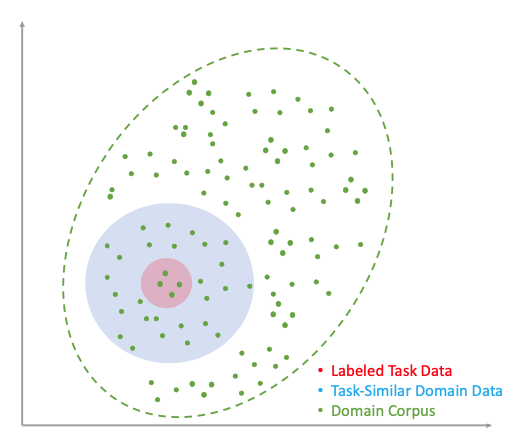
논문의 핵심 아이디어. 거대한 도메인 데이터(녹색) 중에서 목표 작업(적색)과 가장 관련성이 높은 '알짜배기' 데이터(청색)만 선별하여 학습 효율을 극대화합니다.
전략 1: 특정 시험을 준비하는 모범생 (ETS-DACP)
만약 여러분의 목표가 '금융 뉴스 감성 분석'처럼 명확하다면, 이 방법이 정답입니다.
- 어떻게? 전체 금융 데이터 중에서 우리가 풀어야 할 문제(Task Data)와 가장 유사한 내용의 데이터만 골라냅니다. 마치 시험을 앞두고 기출문제와 가장 비슷한 유형의 문제집만 집중적으로 푸는 것과 같습니다.
- 언제? 특정 다운스트림 태스크의 성능을 극대화하고 싶을 때 사용합니다.
전략 2: 특정 시험 없이 실력을 키우는 실력파 (ETA-DACP)
딱히 정해진 목표는 없지만, 전반적인 '금융 전문가' 모델을 만들고 싶을 때 사용하는 방법입니다. 이 전략은 두 가지 기준으로 데이터를 평가합니다.
-
참신성 (Novelty): 모델을 '깜짝' 놀라게 할 데이터
- 모델이 이전에 본 적 없거나 이해하기 어려워하는(Perplexity가 높은) 데이터를 선택합니다. 모델에게는 이런 데이터가 새로운 지식을 배울 수 있는 최고의 교재입니다.
-
다양성 (Diversity): 편식하지 않는 데이터
- 다양한 단어와 문장 구조(높은 Token Type Entropy)를 가진 데이터를 선택합니다. 이는 모델이 편협한 지식에 갇히지 않고, 풍부한 언어 구사 능력을 갖추도록 돕습니다.
이 두 전략 모두 데이터를 정렬해 상위 N%만 선택하는 Hard Sampling 방식이 가중치를 부여해 확률적으로 뽑는 방식보다 더 효과적이었습니다. 어중간한 데이터는 아예 빼는 것이 낫다는 실용적인 교훈을 주죠.
3. 결과는 놀라웠다: 비용은 1/10, 성능은 그 이상
이러한 데이터 선택 전략의 결과는 정말 인상적입니다.
| 모델 | 사용 데이터 | 금융 태스크 평균 성능 | 범용 지식 수준 |
|---|---|---|---|
| Pythia-1B (기반 모델) | - | 53.14 | 유지 (기준) |
| DACP (무작위 학습) | 금융 데이터 전체 (100%) | 55.14 | 약간 저하 |
| ETS-DACP (선별 학습) | 유사도 기반 선별 데이터 (10%) | 59.76 | 유지 |
| ETA-DACP (선별 학습) | 엔트로피 기반 선별 데이터 (10%) | 58.43 | 유지 |
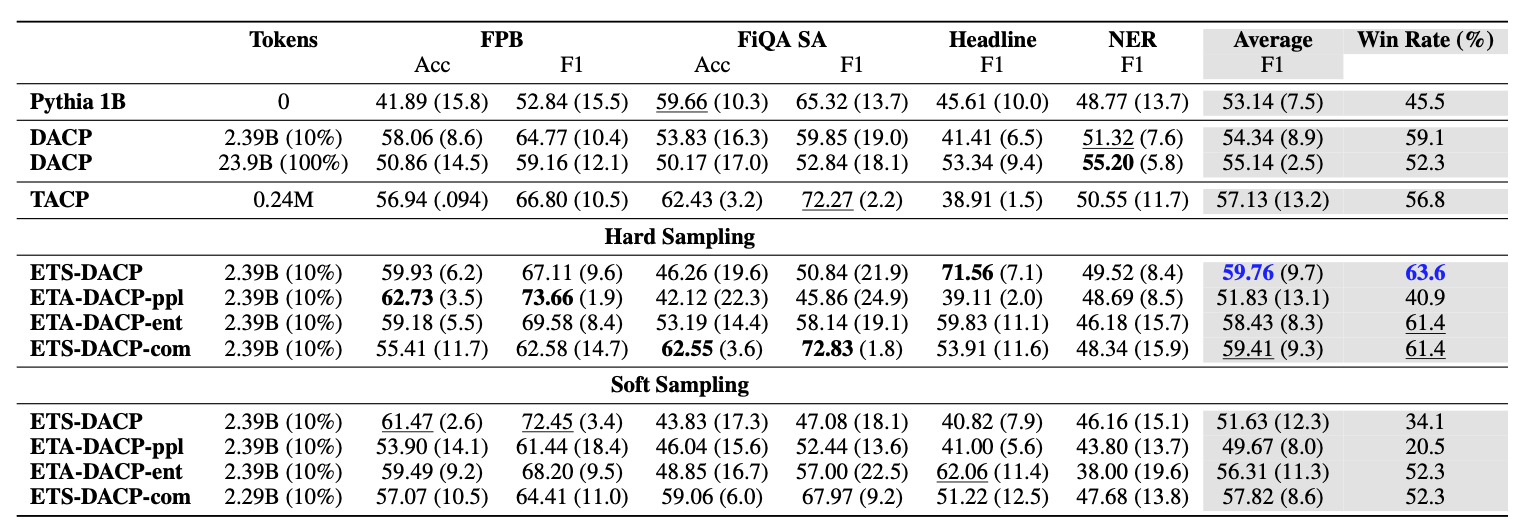
결과가 말해주는 핵심은 두 가지입니다.
-
압도적인 효율성: 전체 데이터의 10%만 현명하게 골라 학습시킨 모델(
ETS-DACP)이 100%를 모두 학습한 모델(DACP)보다 금융 분야에서 훨씬 뛰어난 성능을 보였습니다. 비용은 10분의 1로 줄이고 성능은 오히려 높인 것입니다. -
'상식'을 잃지 않는 전문가: 더 놀라운 점은, 금융 전문가가 되면서도 기존에 알던 일반 상식(범용 태스크 성능)은 거의 잃지 않았다는 점입니다. 특정 분야만 파고들다 다른 분야는 바보가 되는 '지식 재앙적 망각(Catastrophic Forgetting)' 문제를 성공적으로 피했습니다.
실제로 이렇게 학습된 FinPythia 모델은 SPAC이나 Cathie Wood 같은 최신 금융 용어와 이슈에 대해 기존 모델보다 훨씬 정확하고 상세한 답변을 생성해냈습니다.
4. 개발자를 위한 결론: 이제 우리도 할 수 있다
이 논문이 우리 개발자들에게 주는 메시지는 명확합니다.
"대규모 자본 없이도, 똑똑한 데이터 전략만 있다면 누구나 최고 수준의 도메인 전문가 LLM을 만들 수 있다."
이제 값비싼 A to Z 학습은 잊으세요. 좋은 오픈소스 기반 모델을 선택하고, 여러분의 도메인 데이터를 모아, 오늘 소개한 '알짜배기' 데이터 선별 전략을 적용해 보세요. 데이터의 '양'에 집착하기보다 '질'을 높이는 것, 이것이 바로 적은 비용으로 최대의 효과를 내는 LLM 튜닝의 핵심입니다.
# Comments
아직 댓글이 없습니다. 첫 댓글을 남겨보세요.