2026년 1월 12-18일 주요 AI 논문 심층 분석
2026년 1월 12-18일 주요 AI 논문 심층 분석 - Learning Latent Action World Models, DroPE, Dr. Zero, AgeMem, Focus, Agent-as-a-Judge 등
2026년 1월 12-18일 주요 AI 논문 심층 분석
1. Learning Latent Action World Models In The Wild (Meta AI)
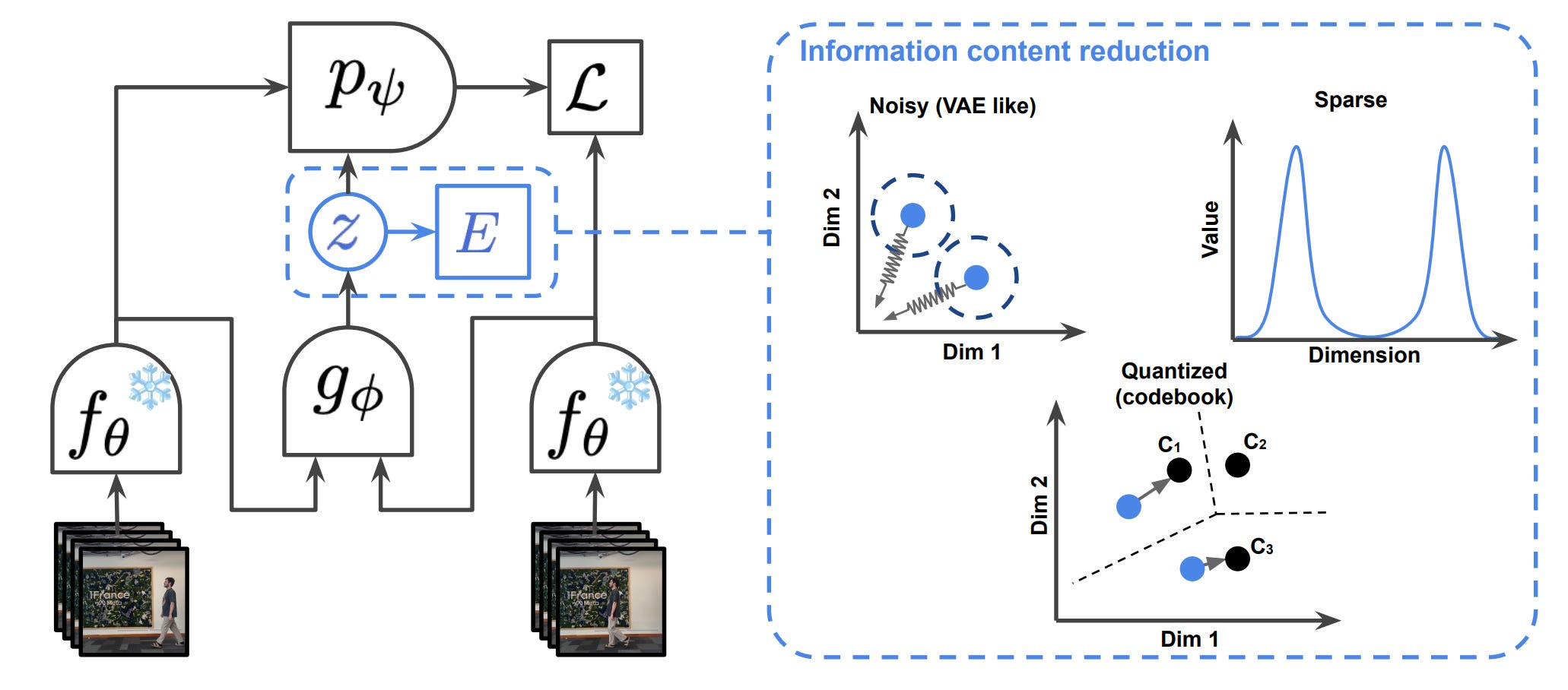
배경 및 문제
기존 world model은 에이전트가 환경과 상호작용하는 방식을 학습하는데, 대부분 명시적인 "액션 라벨"이 필요했습니다. 로봇 시뮬레이션이나 게임에서는 가능하지만, 유튜브 영상처럼 실제 세계의 비디오에서는 이런 라벨을 얻을 수 없습니다.
핵심 접근법
- 잠재 액션(Latent Action) 학습: 명시적 라벨 대신, 연속적이면서도 제약된 잠재 공간에서 액션을 표현합니다.
- 교차 비디오 전이: 한 비디오에서 학습한 환경 변화를 다른 비디오에 적용할 수 있습니다.
- 범용 인터페이스: 다양한 embodiment에도 불구하고 범용적으로 사용할 수 있는 컨트롤러를 학습시킵니다.
결과: 액션 조건부 베이스라인과 동등한 계획 성능을 달성하며, 액션 라벨이 전혀 필요 없었습니다.
2. Extending Context by Dropping Positional Embeddings (DroPE)
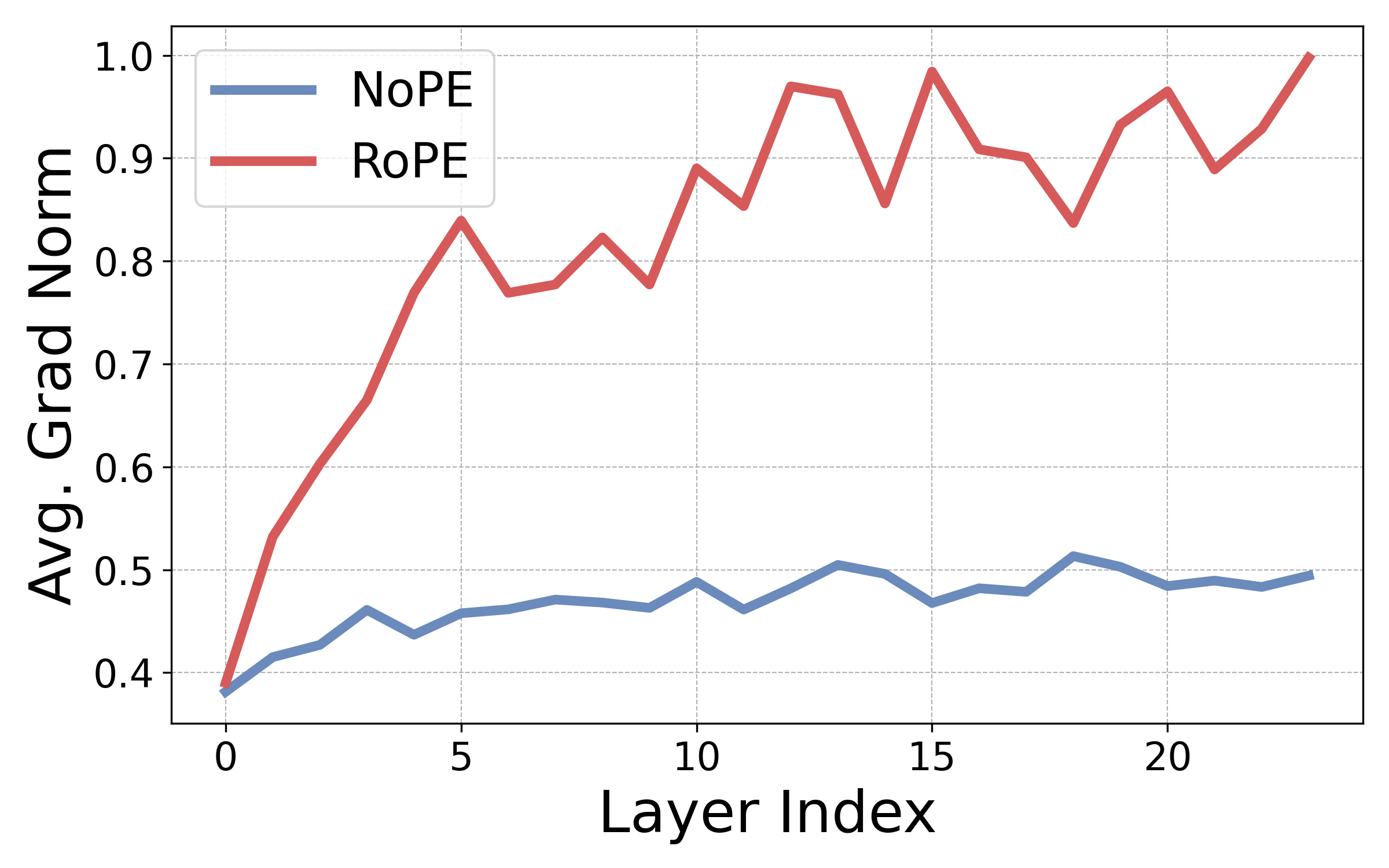
배경 및 문제
언어 모델이 사전학습 시 사용한 것보다 긴 텍스트를 처리하려면 "컨텍스트 윈도우 확장"이 필요합니다. 기존 RoPE 스케일링 방법은 perplexity는 유지하지만, 유효 컨텍스트를 "자르는" 효과가 있어 긴 범위의 정보 검색 작업에서 실패합니다.
핵심 통찰
위치 임베딩은 "학습 시 비계(scaffold)" 역할을 합니다. 학습 중에는 유용하지만, 테스트 시 학습 길이를 초과하면 오히려 방해가 됩니다.
방법론
- RoPE 기반 모델을 학습하거나 가져옵니다
- 사전학습 후 위치 임베딩을 완전히 제거합니다
- 원래 사전학습 예산의 0.5-2%만 사용해 짧은 재보정을 수행합니다
결과
- 5B 토큰 미만의 재보정으로 95%+ 문맥 내 성능 회복
- needle-in-haystack 작업에서 RoPE 스케일링 방법을 크게 능가
- LongBench에서 SmolLM 점수 10배 향상
3. Self-Evolving Search Agents Without Training Data (Dr. Zero)
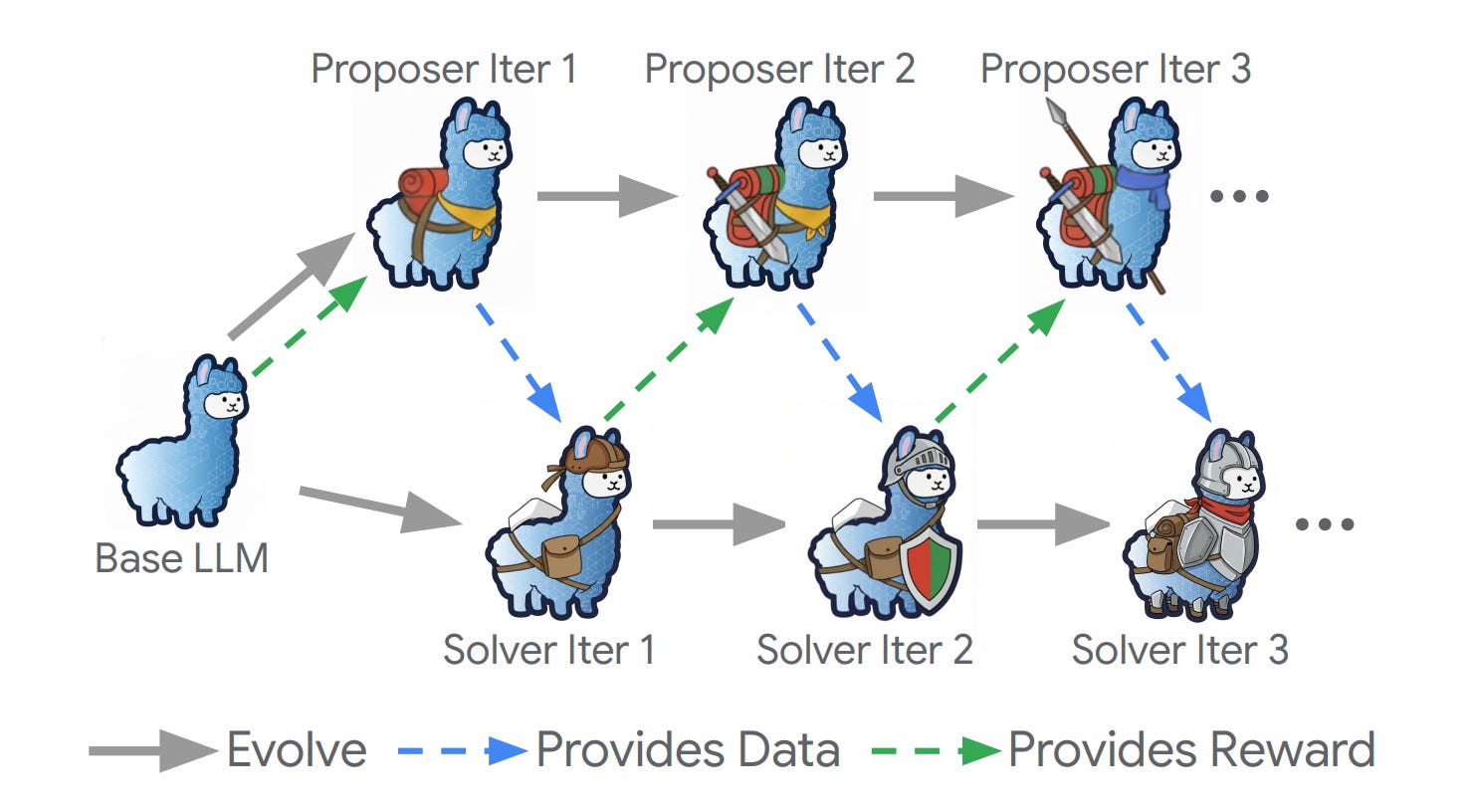
배경 및 문제
멀티턴 검색 에이전트를 개발하려면 일반적으로 인간이 라벨링한 대량의 학습 데이터가 필요합니다.
핵심 접근법
- 자기진화 루프: Proposer가 다양한 질문을 생성하고, Solver가 이를 학습합니다. Solver가 향상되면 난이도가 자동으로 증가합니다.
- Hop-Grouped Relative Policy Optimization (HRPO): 구조적으로 유사한 질문을 클러스터링하여 그룹 수준의 베이스라인을 구축합니다.
결과: 완전 지도학습 검색 에이전트와 동등하거나 우수한 성능을 보이며, 라벨링된 데이터 없이도 복잡한 멀티턴 추론 능력이 발현됩니다.
4. Unified Long-Term and Short-Term Memory for LLM Agents (AgeMem)
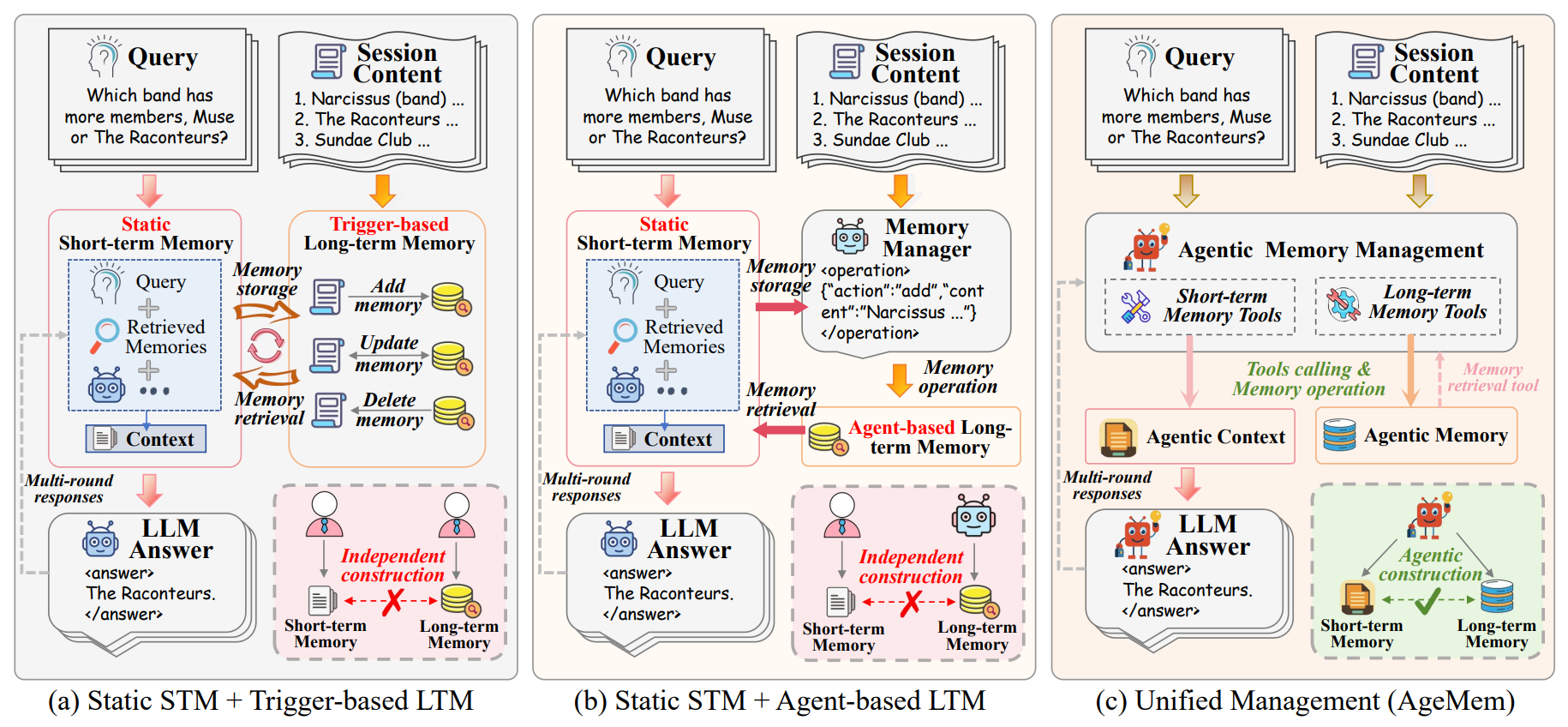
배경 및 문제
AI 에이전트도 단기 메모리와 장기 메모리가 필요합니다. 기존 시스템은 이 둘을 별도로 처리하고 고정된 규칙을 사용해 유연성이 부족했습니다.
핵심 혁신
- 통합 메모리 관리: 장기/단기 메모리를 단일 학습 가능한 정책으로 통합하여 작업 요구사항에 따라 동적으로 적응합니다.
- 도구로서의 메모리: 메모리 연산(저장, 검색, 업데이트, 요약, 삭제)을 호출 가능한 도구로 노출합니다.
- 점진적 강화학습: "step-wise GRPO" 알고리즘을 사용합니다.
결과: 5개 장기 벤치마크에서 작업 성능, 메모리 품질, 컨텍스트 효율성을 동시에 향상시킵니다.
5. Active Context Compression for LLM Agents (Focus)
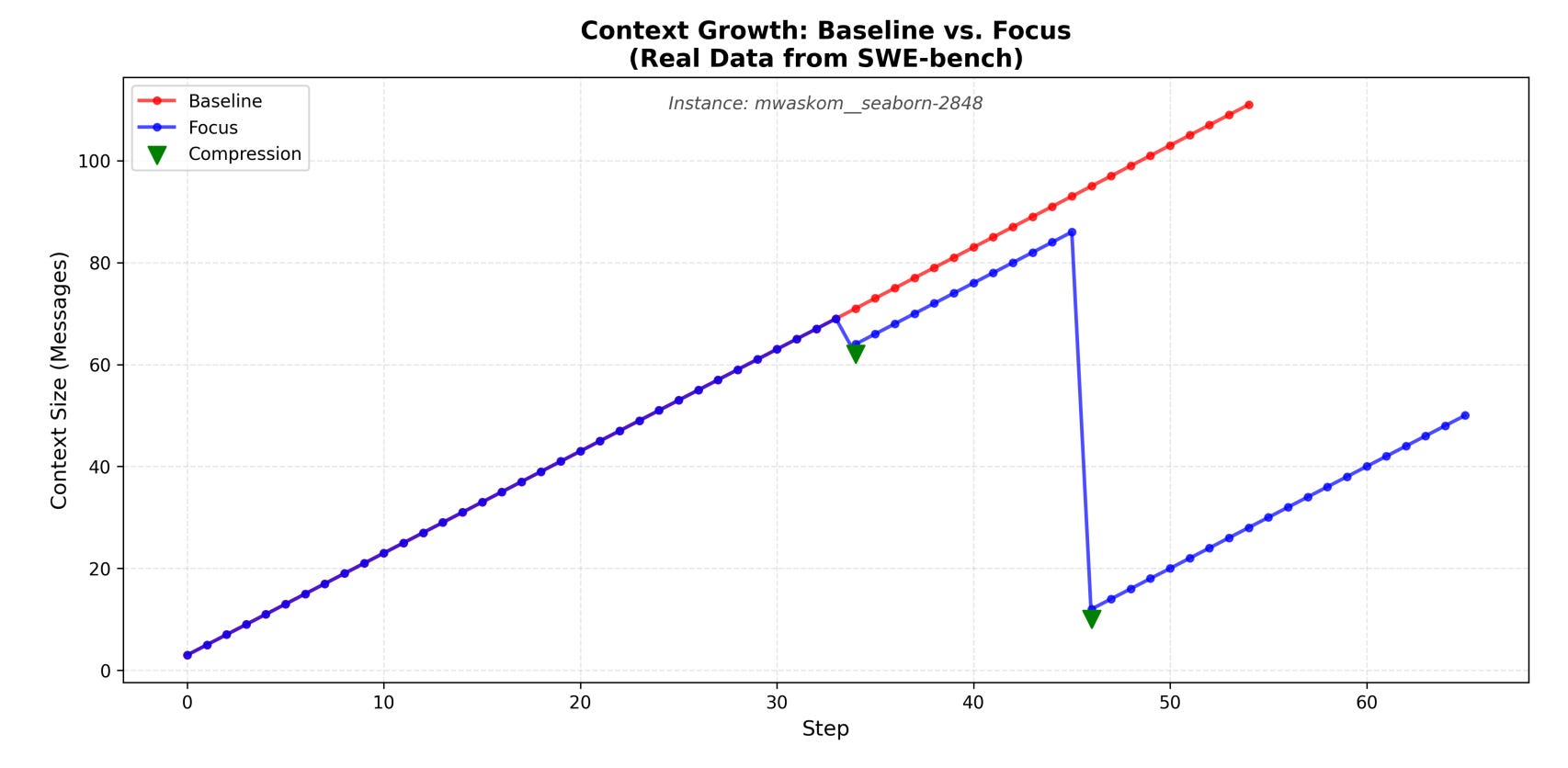
배경 및 문제
LLM 에이전트가 긴 작업을 수행하면 상호작용 히스토리가 계속 쌓입니다. 이로 인해:
- 계산 비용이 기하급수적으로 증가
- 처리 지연 악화
- 과거의 무관한 실수들로 인한 추론 품질 저하
생물학적 영감
점균류의 탐색 패턴에서 영감을 받았습니다. 이 생물은 자원과 경로를 효율적으로 관리하며, 불필요한 경로는 제거하고 중요한 발견은 강화합니다.
핵심 접근법
- 자율적 메모리 관리: 에이전트가 스스로 중요한 발견을 저장할 시점을 선택하고 원시 상호작용 기록을 제거합니다.
- 지식 블록: 학습한 내용을 영구적인 "Knowledge" 블록으로 통합합니다.
- 프로덕션 수준 도구: 영구 bash와 문자열 대체 편집기를 포함한 도구킷 사용
결과
- SWE-bench Lite에서 Claude Haiku 4.5 테스트 시 토큰 소비 22.7% 감소 (14.9M → 11.5M)
- 정확도는 동일하게 60% 유지
- 특정 인스턴스에서 최대 57% 감소
6. Agent-as-a-Judge (종합 서베이)
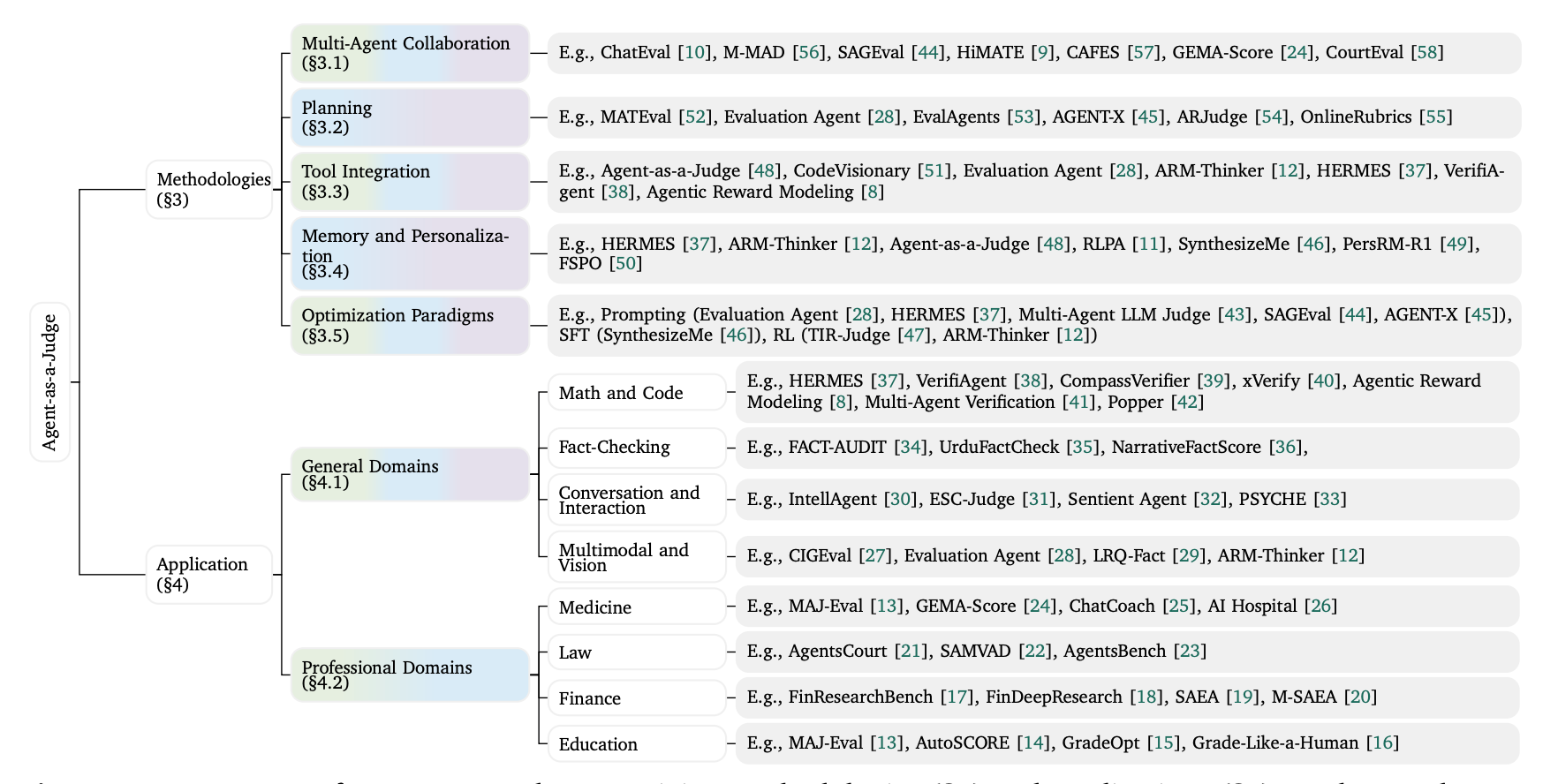
배경 및 문제
AI 시스템을 평가하는 일이 점점 복잡해지면서, 전통적인 단일 패스 LLM 판정자가 불충분해졌습니다.
주요 내용
- LLM-as-a-Judge의 한계 식별: 전통적 LLM 판정자의 제약사항과 에이전틱 접근법이 어떻게 극복하는지 분석합니다.
- 발전 분류체계: LLM 기반 평가에서 에이전틱 평가로의 패러다임 전환을 체계화한 분류체계를 구축합니다.
- 에이전틱 능력: 계획, 도구 증강 검증, 다중 에이전트 협업, 지속 메모리를 통해 더 견고한 평가가 가능합니다.
의미
평가 자체가 정적인 판단에서 동적이고 다단계 검증이 가능한 에이전트 기반 시스템으로 진화하고 있습니다.
7. Efficient Lifelong Memory for LLM Agents (SimpleMem)
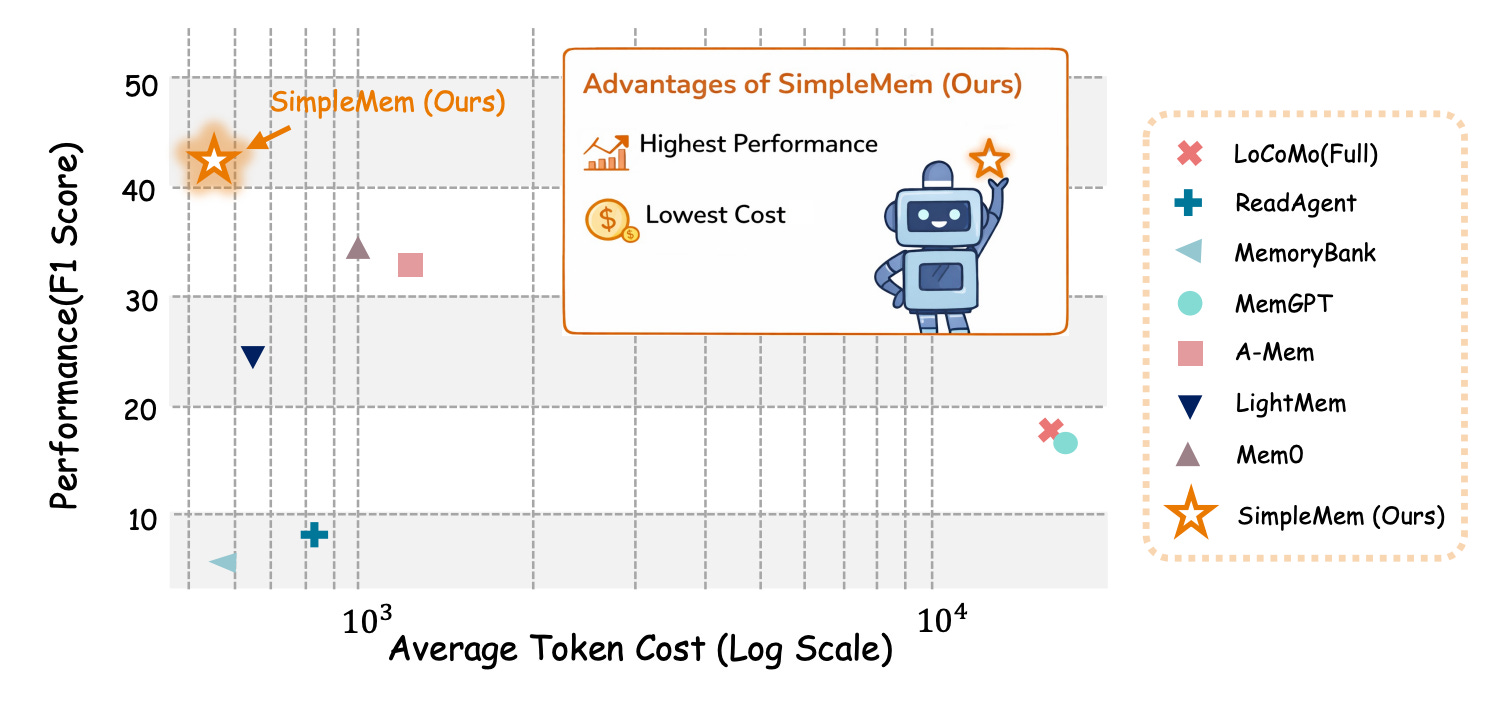
배경 및 문제
LLM 에이전트가 포괄적인 장기 메모리를 유지하면서도 추론 시 토큰 오버헤드를 최소화하는 것은 근본적인 긴장 관계입니다.
핵심 접근법
1단계 - 의미론적 구조화 압축
비구조화된 상호작용을 필터링하여 컴팩트한 다중 뷰 인덱스 메모리 단위로 변환합니다.
2단계 - 재귀적 메모리 통합
비동기 프로세스가 관련 메모리 단위를 더 높은 수준의 표현으로 통합하여 중복을 줄입니다.
3단계 - 적응형 쿼리 인식 검색
쿼리 복잡도에 따라 검색 범위를 동적으로 조정합니다.
결과
- 베이스라인 대비 F1 점수 26.4% 향상
- 추론 시 토큰 소비 최대 30배 감소
- 응답 품질을 희생하지 않으면서 포괄적 메모리 제공
8. Ministral 3 (Mistral AI)
배경 및 문제
모바일 기기, 엣지 디바이스, 계산 및 메모리가 제한된 환경에서 실행할 수 있는 컴팩트하면서도 강력한 언어 모델이 필요합니다.
방법론
Cascade Distillation: 반복적 가지치기와 지속 학습을 통해 더 큰 모델에서 작은 모델로 지식을 증류합니다.
모델 라인업
- 3B, 8B, 14B 파라미터 버전
- 각 크기마다 3가지 변형: 사전학습, 인스트럭션 파인튜닝, 추론 변형
- 통합 이미지 이해 기능
- Apache 2.0 라이선스로 오픈소스
의미: 강력한 AI를 데이터센터가 아닌 사용자의 기기에서 직접 실행할 수 있게 하여, 프라이버시 향상과 지연 시간 감소를 가능하게 합니다.
9. UniversalRAG
배경 및 문제
실제 지식 베이스는 텍스트, 이미지, 비디오 등 여러 데이터 타입이 혼재되어 있습니다. 기존 멀티모달 RAG는 다양한 모달리티를 단일 임베딩 공간에 억지로 넣으려 하는데, 이렇게 하면 임베딩이 의미가 아닌 모달리티별로 클러스터링되어 검색 품질이 떨어집니다.
핵심 접근법
모달리티 인식 라우팅: 단일 임베딩 공간 대신, 각 쿼리에 대해 적절한 코퍼스와 세분성을 동적으로 선택합니다.
이종 소스 처리
- 여러 데이터 타입을 각각의 강점을 살려 처리
- 다양한 세분성 수준(문단, 섹션, 전체 문서 등) 지원
- 쿼리 의도에 따라 최적의 검색 전략 선택
결과: 10개 벤치마크에서 단일모달 RAG와 통합 멀티모달 RAG 베이스라인을 모두 능가합니다.
10. MemRL
배경 및 문제
LLM 에이전트가 새로운 경험에서 학습하려면 일반적으로 비용이 많이 드는 재학습이 필요합니다.
핵심 아이디어
고정된 언어 모델의 추론 능력과 진화하는 메모리 시스템을 분리합니다. 모델 자체는 변경하지 않고 메모리만 개선합니다.
Two-Phase Retrieval 메커니즘
1단계 - 의미론적 필터링
후보 메모리를 의미론적 관련성으로 필터링합니다.
2단계 - Q-value 기반 랭킹
필터링된 후보들을 학습된 Q-value로 순위를 매깁니다.
학습 메커니즘
에이전트가 작업을 수행하면서 어떤 메모리가 유용했는지 경험하고, 이를 통해 Q-value가 업데이트됩니다.
결과: HLE, BigCodeBench, ALFWorld, Lifelong Agent Bench 등 여러 벤치마크에서 기존 방법들을 능가하며, 모델 재학습 없이 지속적 개선이 가능합니다.
주요 트렌드 분석
이번 주 논문들에서 발견되는 공통 테마:
-
메모리 관리의 중요성: 논문 4, 5, 7, 10이 모두 에이전트 메모리에 집중하고 있어, 장기 작업에서 효율적인 메모리가 핵심 과제임을 보여줍니다.
-
학습 데이터 의존성 감소: 논문 1과 3은 명시적 라벨 없이 학습하는 방법을 제시하며, AI 개발의 데이터 병목을 해결하려는 시도입니다.
-
컨텍스트 효율성: 논문 2, 5, 7은 모두 토큰 소비를 줄이면서 성능을 유지하는 방법을 제안합니다.
-
에이전틱 AI의 진화: 논문 6이 평가 자체도 에이전트화되고 있음을 보여주며, AI가 단순 모델에서 자율 시스템으로 진화하는 큰 흐름을 반영합니다.
Cite: https://nlp.elvissaravia.com/p/top-ai-papers-of-the-week-093
# Comments
아직 댓글이 없습니다. 첫 댓글을 남겨보세요.